TensorFlow Scala
type-safe linear algebra, tensors, and neural networks
This library is a Scala API for https://www.tensorflow.org. It attempts to provide most of the functionality provided by the official Python API, while at the same type being strongly-typed and adding some new features. It is a work in progress and a project I started working on for my personal research purposes. Much of the API should be relatively stable by now, but things are still likely to change. That is why there is no official release of this library yet.
Please refer to the main website for documentation and tutorials. Here are a few useful links:
Main Features
-
Easy manipulation of tensors and computations involving tensors (similar to NumPy in Python):
val t1 = Tensor( 1.2, 4.5) val t2 = Tensor(-0.2, 1.1) t1 + t2 == Tensor(1.0, 5.6) -
High-level API for creating, training, and using neural networks. For example, the following code shows how simple it is to train a multi-layer perceptron for MNIST using TensorFlow for Scala. Here we omit a lot of very powerful features such as summary and checkpoint savers, for simplicity, but these are also very simple to use.
import org.platanios.tensorflow.api._ import org.platanios.tensorflow.api.tf.learn._ import org.platanios.tensorflow.data.loaders.MNISTLoader // Load and batch data using pre-fetching. val dataSet = MNISTLoader.load(Paths.get("/tmp")) val trainImages = DatasetFromSlices(dataSet.trainImages) val trainLabels = DatasetFromSlices(dataSet.trainLabels) val trainData = trainImages.zip(trainLabels) .repeat() .shuffle(10000) .batch(256) .prefetch(10) // Create the MLP model. val input = Input(UINT8, Shape(-1, 28, 28)) val trainInput = Input(UINT8, Shape(-1)) val layer = Flatten() >> Cast(FLOAT32) >> Linear(128, name = "Layer_0") >> ReLU(0.1f) >> Linear(64, name = "Layer_1") >> ReLU(0.1f) >> Linear(32, name = "Layer_2") >> ReLU(0.1f) >> Linear(10, name = "OutputLayer") val trainingInputLayer = Cast(INT64) val loss = SparseSoftmaxCrossEntropy() >> Mean() val optimizer = GradientDescent(1e-6) val model = Model(input, layer, trainInput, trainingInputLayer, loss, optimizer) // Create an estimator and train the model. val estimator = Estimator(model) estimator.train(trainData, StopCriteria(maxSteps = Some(1000000)))And by changing a few lines to the following code, you can get checkpoint capability, summaries, and seamless integration with TensorBoard:
loss = loss >> tf.learn.ScalarSummary("Loss") // Collect loss summaries for plotting val summariesDir = Paths.get("/tmp/summaries") // Directory in which to save summaries and checkpoints val estimator = Estimator(model, Configuration(Some(summariesDir))) estimator.train( trainData, StopCriteria(maxSteps = Some(1000000)), Seq( SummarySaverHook(summariesDir, StepHookTrigger(100)), // Save summaries every 1000 steps CheckpointSaverHook(summariesDir, StepHookTrigger(1000))), // Save checkpoint every 1000 steps tensorBoardConfig = TensorBoardConfig(summariesDir)) // Launch TensorBoard server in the backgroundIf you now browse to
https://127.0.0.1:6006while training, you can see the training progress: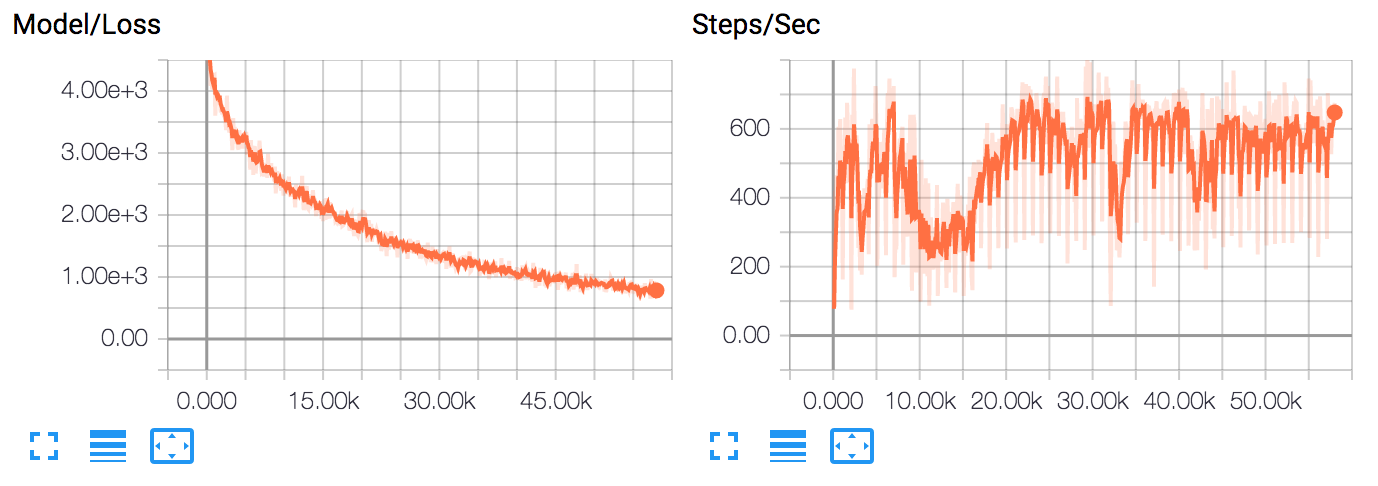
-
Low-level graph construction API, similar to that of the Python API, but strongly typed wherever possible:
import org.platanios.tensorflow.api._ val inputs = tf.placeholder(FLOAT32, Shape(-1, 10)) val outputs = tf.placeholder(FLOAT32, Shape(-1, 10)) val predictions = tf.createWith(nameScope = "Linear") { val weights = tf.variable("weights", FLOAT32, Shape(10, 1), tf.zerosInitializer) tf.matmul(inputs, weights) } val loss = tf.sum(tf.square(predictions - outputs)) val optimizer = tf.train.AdaGrad(1.0) val trainOp = optimizer.minimize(loss) -
Numpy-like indexing/slicing for tensors. For example:
tensor(2 :: 5, ---, 1) // is equivalent to numpy's 'tensor[2:5, ..., 1]' -
Efficient interaction with the native library that avoids unnecessary copying of data. All tensors are created and managed by the native TensorFlow library. When they are passed to the Scala API (e.g., fetched from a TensorFlow session), we use a combination of weak references and a disposing thread running in the background. Please refer to
Disposer.scala, for the implementation.
Funding
Funding for the development of this library has been generously provided by the following sponsors:
|
|
|
|
| CMU Presidential Fellowship awarded to Emmanouil Antonios Platanios |
National Science Foundation Grant #: IIS1250956 |
Air Force Office of Scientific Research Grant #: FA95501710218 |